AI Facefyの最新記事、ニュース、アップデートをご覧ください。専門家の洞察やチュートリアルを入手し、当社の画期的なAI技術とプラットフォーム開発に関する最新情報を入手してください。
AIFacefy で Happy Horse 1.0 を使って、1枚の画像からモーション・音声・実用的なプロンプト付きの短い AI 動画を作成しましょう。
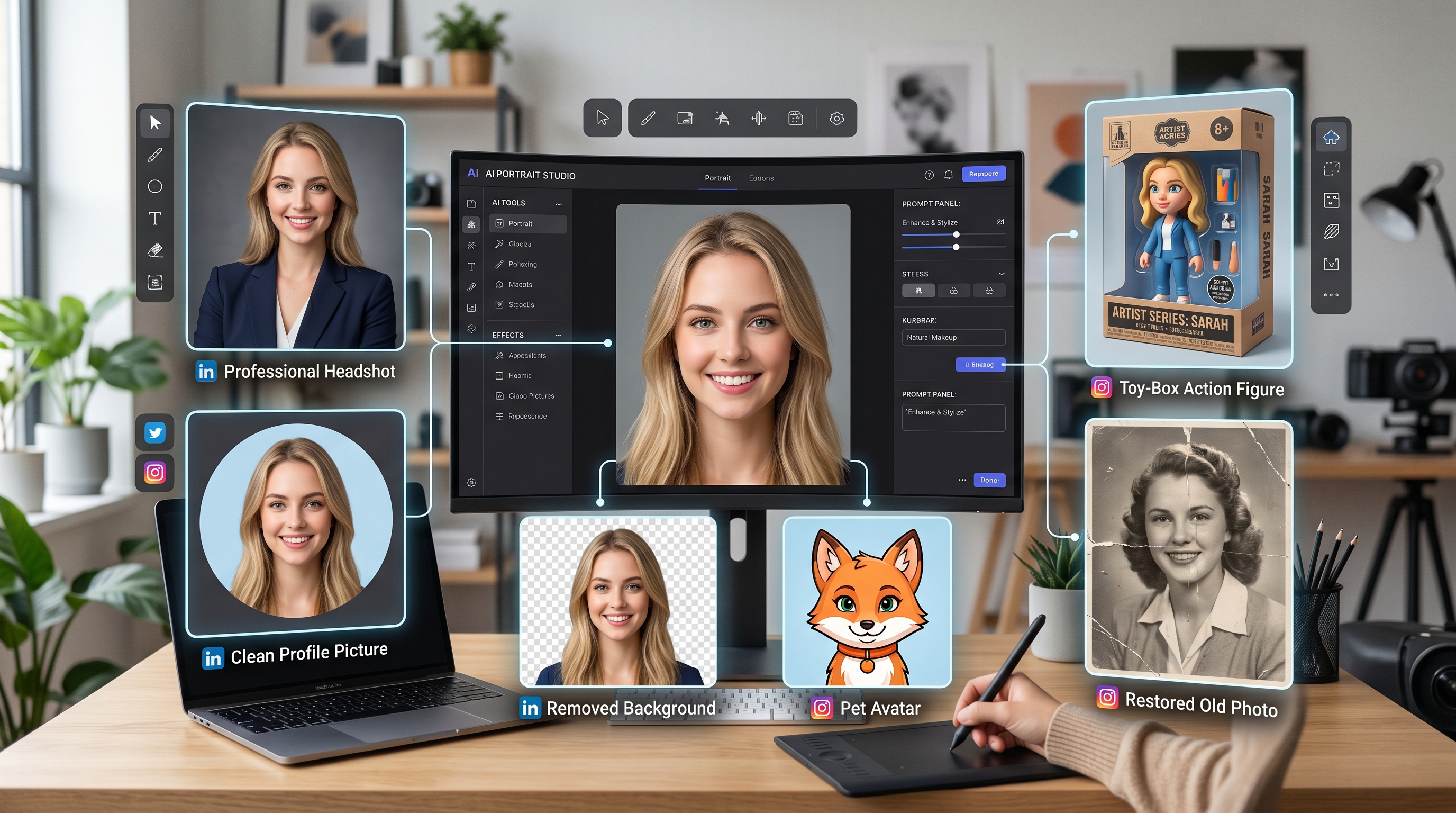
GPT Image 2 と AIFacefy ツールを使って、ヘッドショット、背景、アバター、アクションフィギュア、プロフィール写真を編集しましょう。
GPT Image 2 を探る:新機能、アクセス方法、そしてフォトリアルな人物画像生成で際立つ理由
AIの顔とベビー生成機能を使って、デジタル家族アルバムを作成しましょう。AIFacefyを使えば、キャラクターや将来の子供を簡単かつリアルにイメージできます。
赤ちゃん・ペット・ミームにも優しい画像からダンスへのワークフローで、AIFacefyを使ってバズるTikTokダンスショートを作ろう。
AI顔評価ツールを使ってポートレートを比較し、最も評価の高かった写真をNano Banana 2で編集・最適化してみましょう。
Seedance 2.0へのアクセス方法、そのAPIステータスの意味、そしてなぜ今最も注目すべきエキサイティングなAI動画ツールの一つになりつつあるのかを学びましょう。
シンプルなワークフローのコツ、プロンプト作成のアドバイス、そして便利な AIFacefy ツールを活用して、Higgsfield のモーションコントロールがどのように AI 動画の一貫性を向上させるかを学びましょう。
Seedance 2.0 の実践的な強みと限界、20分でできるテスト計画のレビュー――さらに、AIFacefy で類似のワークフローをすばやく試す方法。
Unbiased Mind Video AI レビュー:機能、品質テスト、料金のコツ、そして安定した再現性のある結果を得るために AIFacefy ツールがより良い代替手段となる場合
Kling 3.0がまもなく登場します——何が期待できるのか、Kling 2.6との違い、そしてなぜAIFacefyが今始めるのに最適な場所なのかをご紹介します。
Kling Motion Control を AIFacefy で使って AI ダンス動画を作成しよう — モーションリファレンス、すぐ使えるプロンプト、TikTok・Reels・YouTube Shorts 向けの書き出し(エクスポート)テクニック付き。
ポートレート、製品撮影、ファッションビジュアル、アート制作にすぐ使えるコピー準備済みの Nano Banana Pro プロンプト例を紹介します。さらに、これらのプロンプトを AIFacefy 上で効率よく運用するための実践的なワークフローも解説。初心者から上級者まで、安定した高品質アウトプットを得るためのヒントをまとめています。
シードリーム4.5 AI顔写真エンハンサーの使い方をわかりやすく解説します。数ステップの簡単操作で、肌質や表情を自然に整え、違和感のない仕上がりのままプロ品質のポートレートへアップグレード可能。特別な編集スキルは不要で、わずか数秒で高精細な顔写真を完成させることができます。
AIベビーフェイスジェネレーターを使えば、将来の子供の顔をわずか数秒でシミュレーションできます。写真をアップロードするだけで、リアルで自然な赤ちゃんの予測画像を生成可能。登録不要・無料で試せるAI赤ちゃんジェネレーターを今すぐ体験してみましょう。