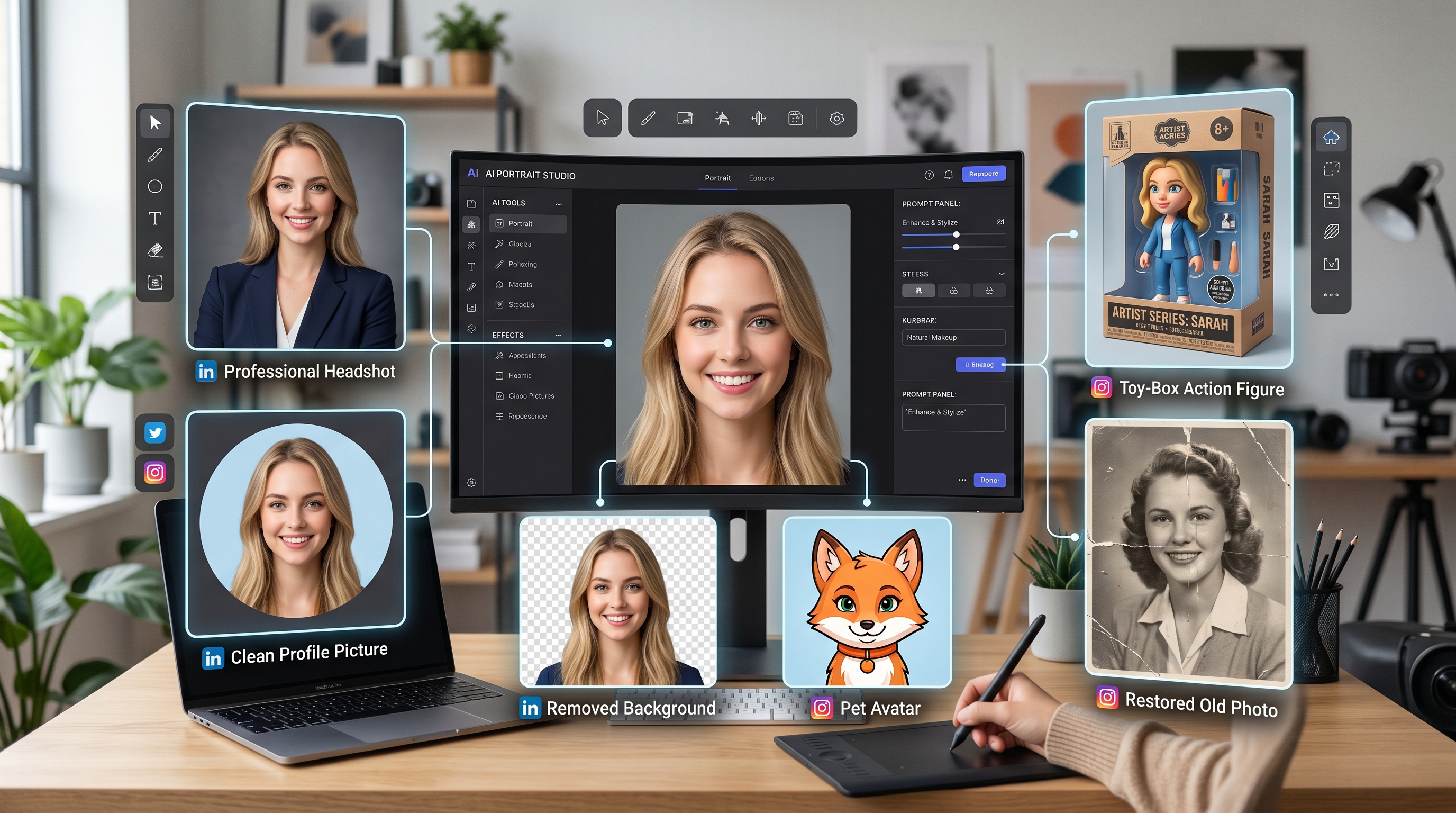
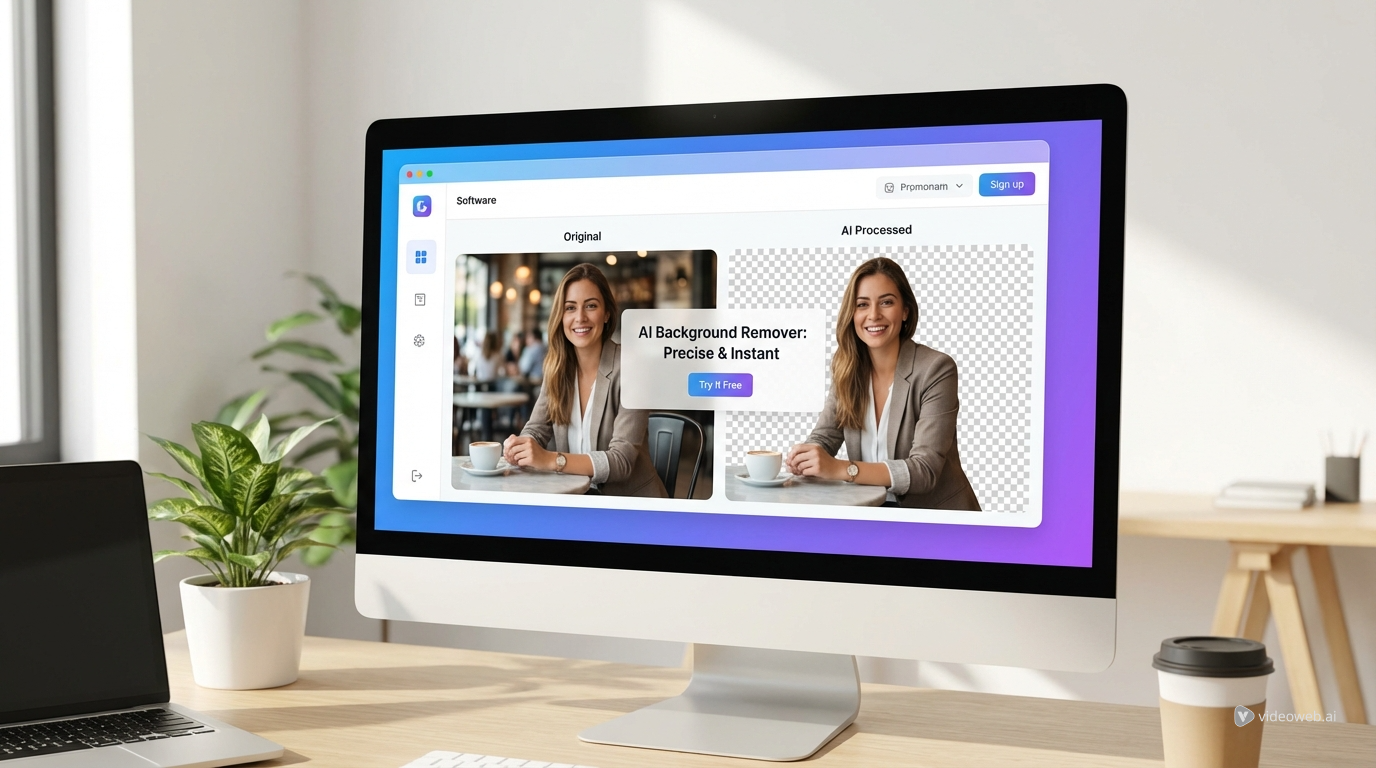
Experience Magic AI Creation Tools with powerful AI Facefy
Instantly transform faces in your images and videos using our advanced AI technology, delivering top-quality results.
Video AI
Photo to VideoImage to VideoText to VideoVideo to VideoAI Dance GeneratorAI Superman GeneratorAI Hulk TranaformationVeo 3.1 AI Video GeneratorKling Motion ControlVidu Q1 Video GeneratorLabubu AI Video GeneratorAI Hair GrowthAI Muscle GrowthAI Squish EffectAI Venom EffectOld Photo AnimationAI Handshake VideoAI Flying Video GeneratorAI Balloon Flyaway
Image AI
AI Image GeneratorGPT Image 2.0Nano Banana 2 AINano Banana Pro AISeedream 4.5 AISeedream 5.0 AIAI Headshot GeneratorAI Hair Cut GeneratorOld Photo RestorerLabubu Toy GeneratorPet to Human GeneratorAI Baby GeneratorAI Action Figure GeneratorGhibli Art GeneratorAI Halloween GeneratorGPT Image 1.5Nano Banana AISeedream 4.0 AI