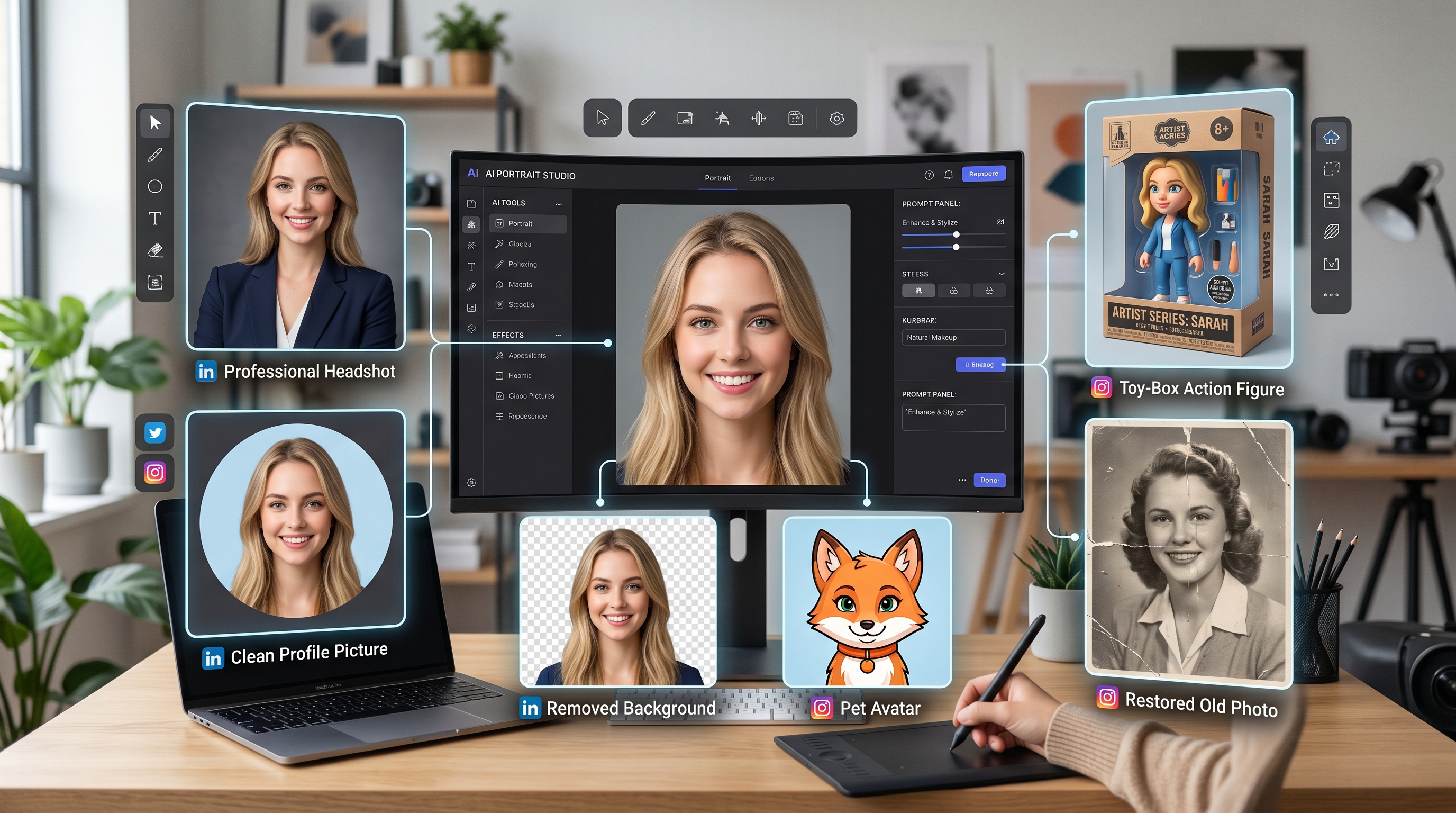
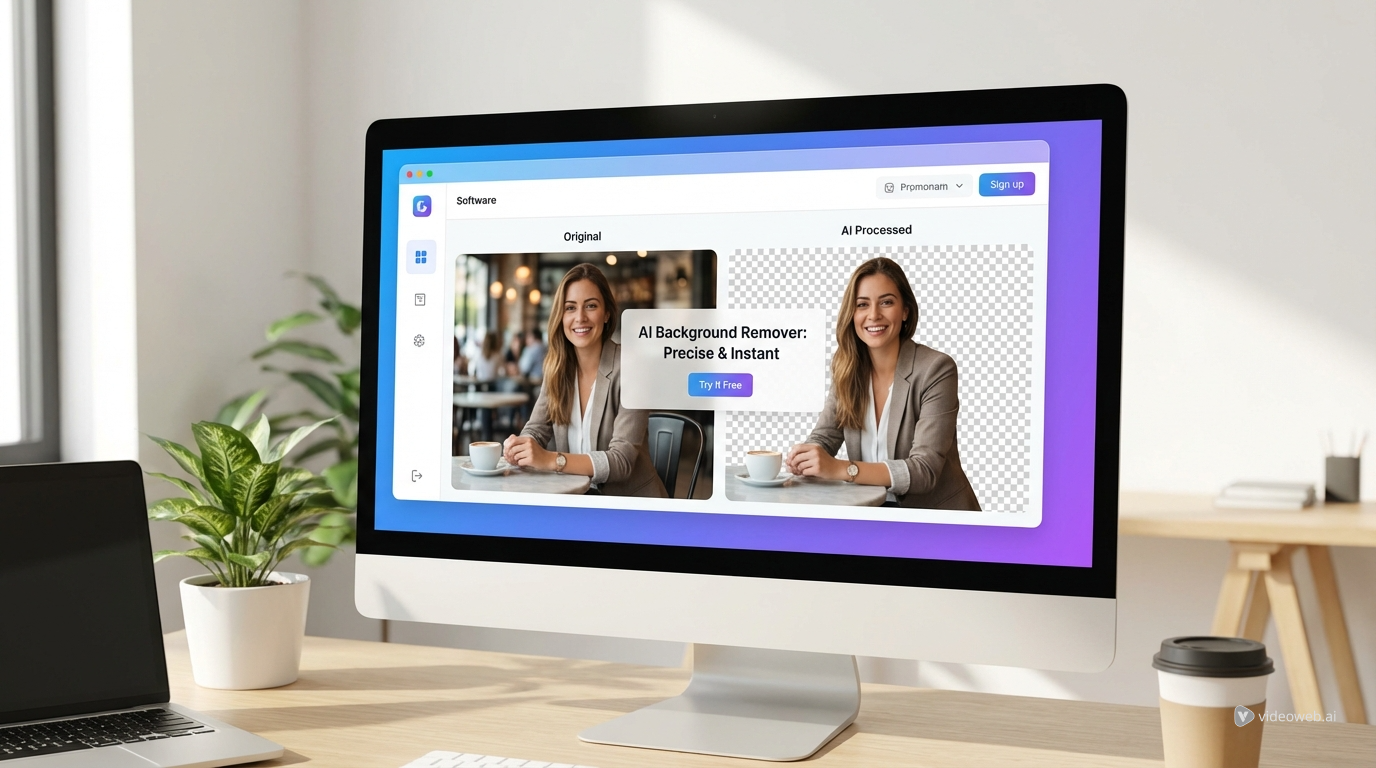
Оцените магию AI-инструментов для творчества с мощным AI Facefy
Мгновенно преобразуйте лица на ваших изображениях и видео с помощью нашей передовой AI-технологии, получая результаты высочайшего качества.
Видео ИИ
Фото в видеоИзображение в видеоТекст в видеоВидео в видеоГенератор танцевальных видео ИИГенератор Супермена ИИИИ трансформация в ХалкаГенератор видео Veo 3.1 ИИКонтроль движения KlingГенератор видео Vidu Q1ИИ генератор видео LabubuAI Рост волосAI Рост мышцAI Эффект сжатияAI Эффект ВеномаАнимация старых фотоAI Видео рукопожатияГенератор летающего объекта ИИИИ улетающий шар
Изображение ИИ
ИИ генератор изображенийGPT Image 2.0Nano Banana 2 AIНано Банана Про ИИSeedream 4.5 ИИSeedream 5.0 AIИИ генератор портретных фотоИИ генератор причёсокРеставратор старых фотоГенератор игрушек LabubuГенератор питомец-в-человекаAI Генератор младенцевAI Генератор фигурокГенератор в стиле GhibliИИ генератор ХэллоуинаGPT Image 1.5Нано Банана ИИSeedream 4.0 ИИ