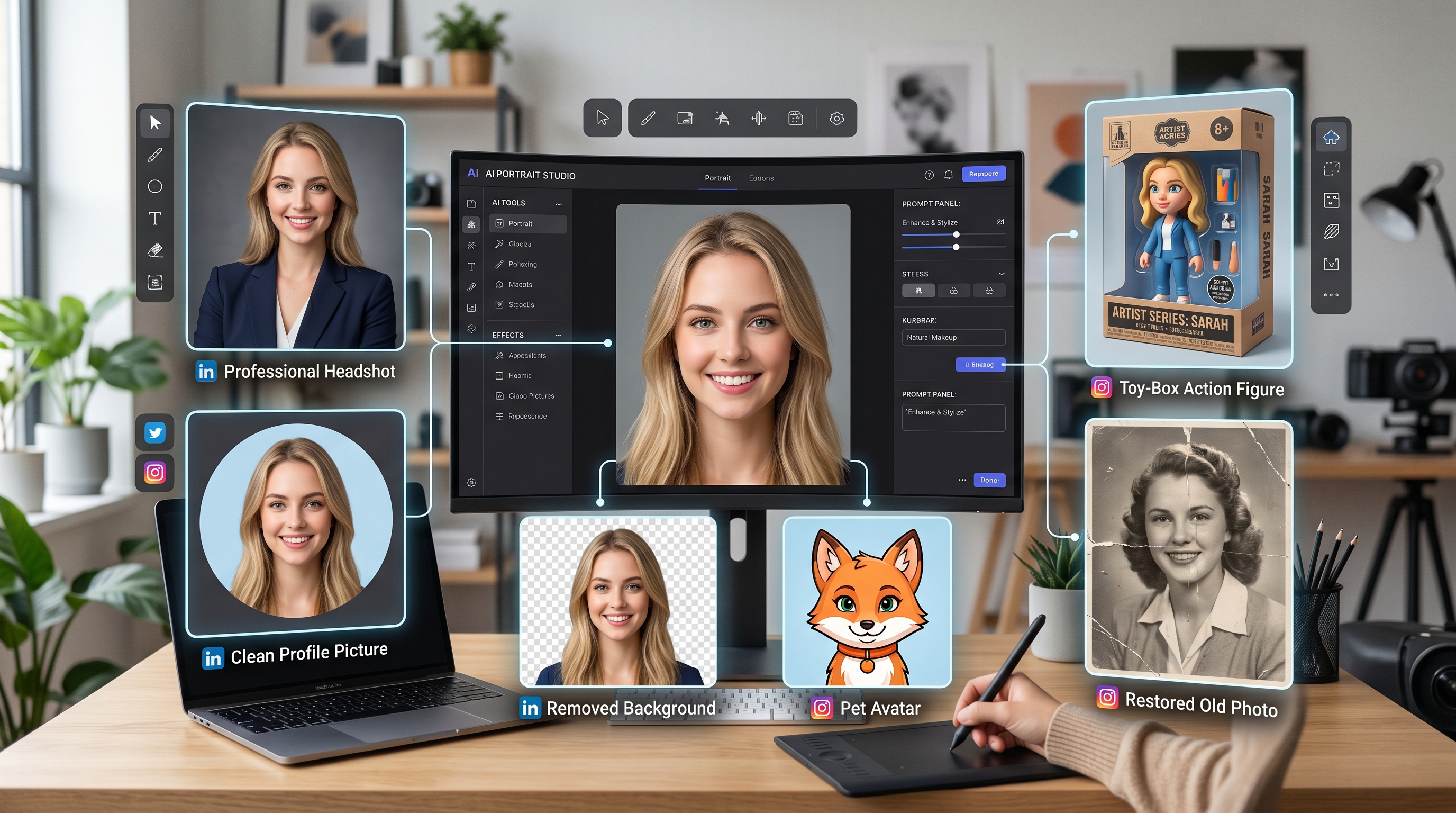
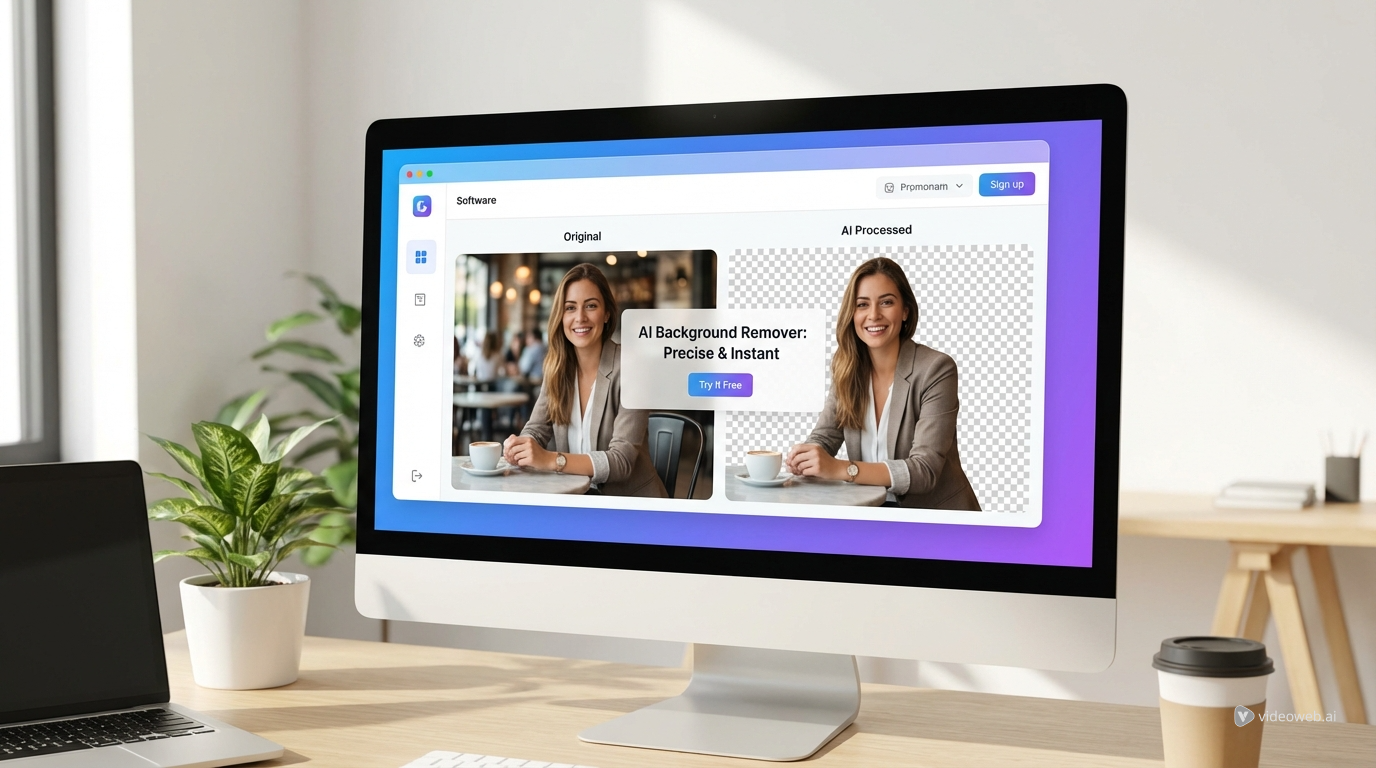
Scopri la Magia degli Strumenti di Creazione AI con il potente AI Facefy
Trasforma istantaneamente i volti nelle tue immagini e video grazie alla nostra tecnologia AI avanzata, per risultati di altissima qualità.
Video AI
Foto a VideoImmagine a VideoTesto a VideoVideo a VideoGeneratore Video di Danza AIGeneratore Superman AITrasformazione Hulk AIGeneratore Video AI Veo 3.1Controllo Movimento KlingGeneratore Video Vidu Q1Generatore Video AI LabubuCrescita Capelli AICrescita Muscolare AIEffetto Squish AIEffetto Venom AIAnimazione Foto AnticheVideo Stretta di Mano AIGeneratore Video di Oggetti Volanti AIPalloncino AI che Vola Via
Immagine AI
Generatore Immagini AIGPT Image 2.0Nano Banana 2 AINano Banana Pro AISeedream 4.5 AISeedream 5.0 AIGeneratore Primo Piano AIGeneratore Taglio Capelli AIRestauro Foto AnticheGeneratore Giocattolo LabubuGeneratore Animale a UmanoGeneratore Bambino AIGeneratore Action Figure AIGeneratore Arte GhibliGeneratore Halloween AIImmagine GPT 1.5Nano Banana AISeedream 4.0 AI