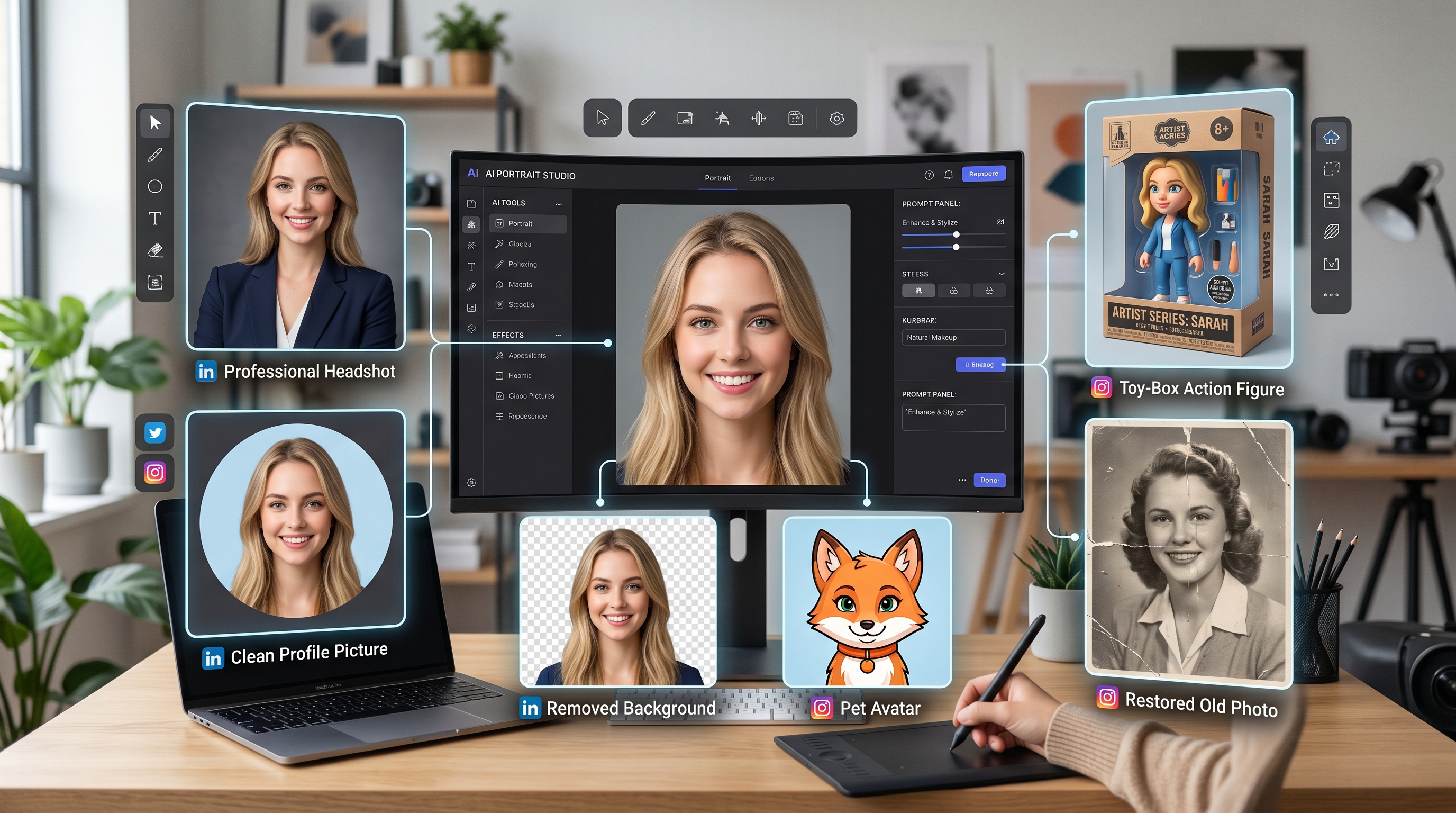
Découvrez la magie des outils de création IA avec le puissant AI Facefy
Transformez instantanément les visages sur vos images et vidéos grâce à notre technologie IA avancée, pour des résultats de qualité supérieure.
Vidéo IA
Photo en vidéoImage en vidéoTexte en vidéoVidéo en vidéoGénérateur de danse IAGénérateur de Superman IATransformation Hulk IAGénérateur Vidéo IA Veo 3.1Contrôle du mouvement KlingGénérateur Vidéo Vidu Q1Générateur de vidéos Labubu IACroissance des cheveux IACroissance musculaire IAEffet IA SquishEffet IA VenomAnimation de vieilles photosVidéo de poignée de main IAGénérateur de Vidéos d'Objets Volants IAIA Ballon Qui S’Envole
Image IA
Générateur d'images IAGPT Image 2.0Nano Banana 2 AINano Banana Pro IASeedream 4.5 IASeedream 5.0 AIGénérateur de portrait IAGénérateur de coupe de cheveux IARestauration de vieilles photosGénérateur de jouets LabubuGénérateur animal en humainGénérateur de bébé IAGénérateur de figurines IAGénérateur d'art GhibliGénérateur d'Halloween IAImage GPT 1.5IA Nano BananaSeedream 4.0 IA