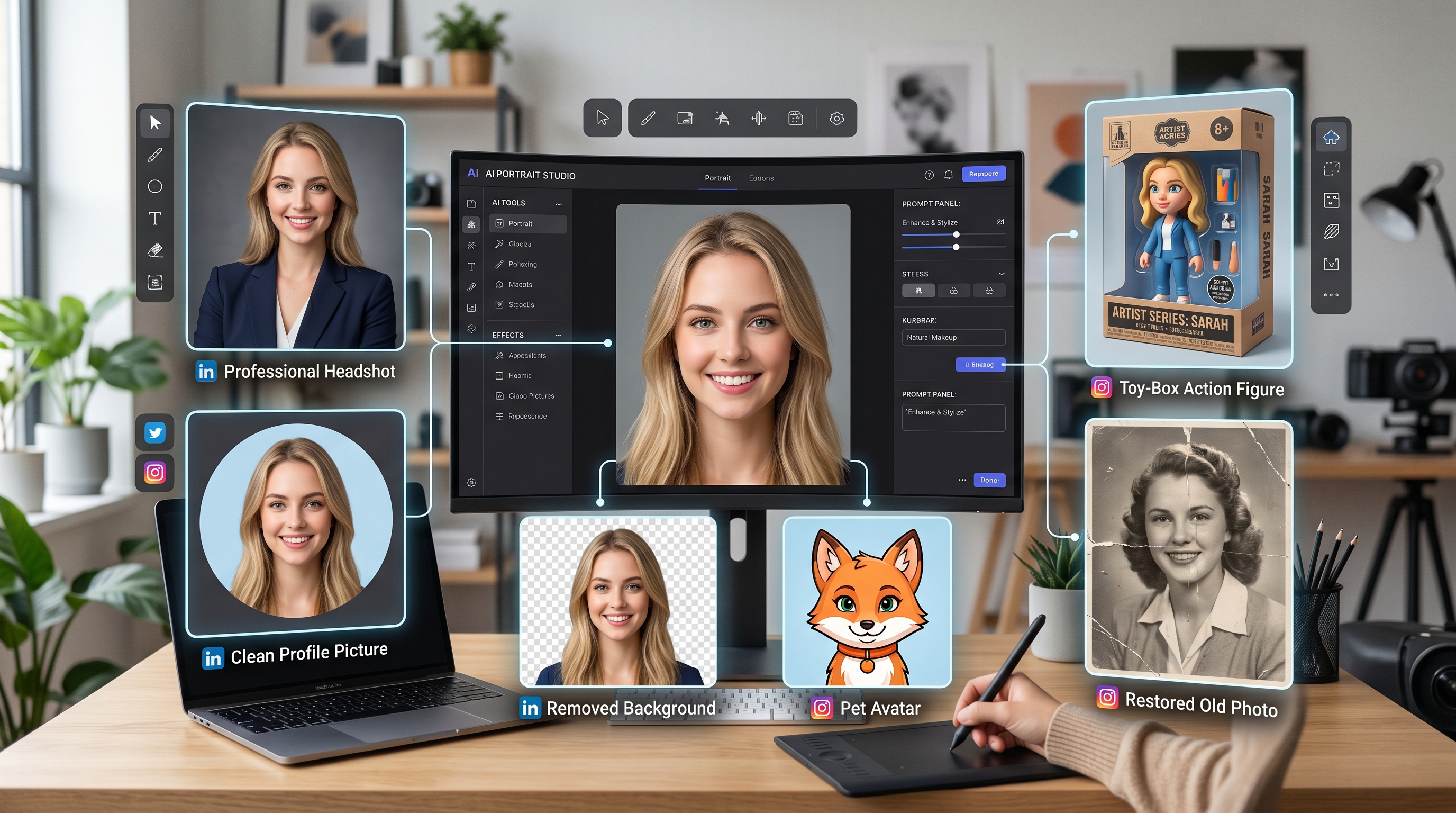
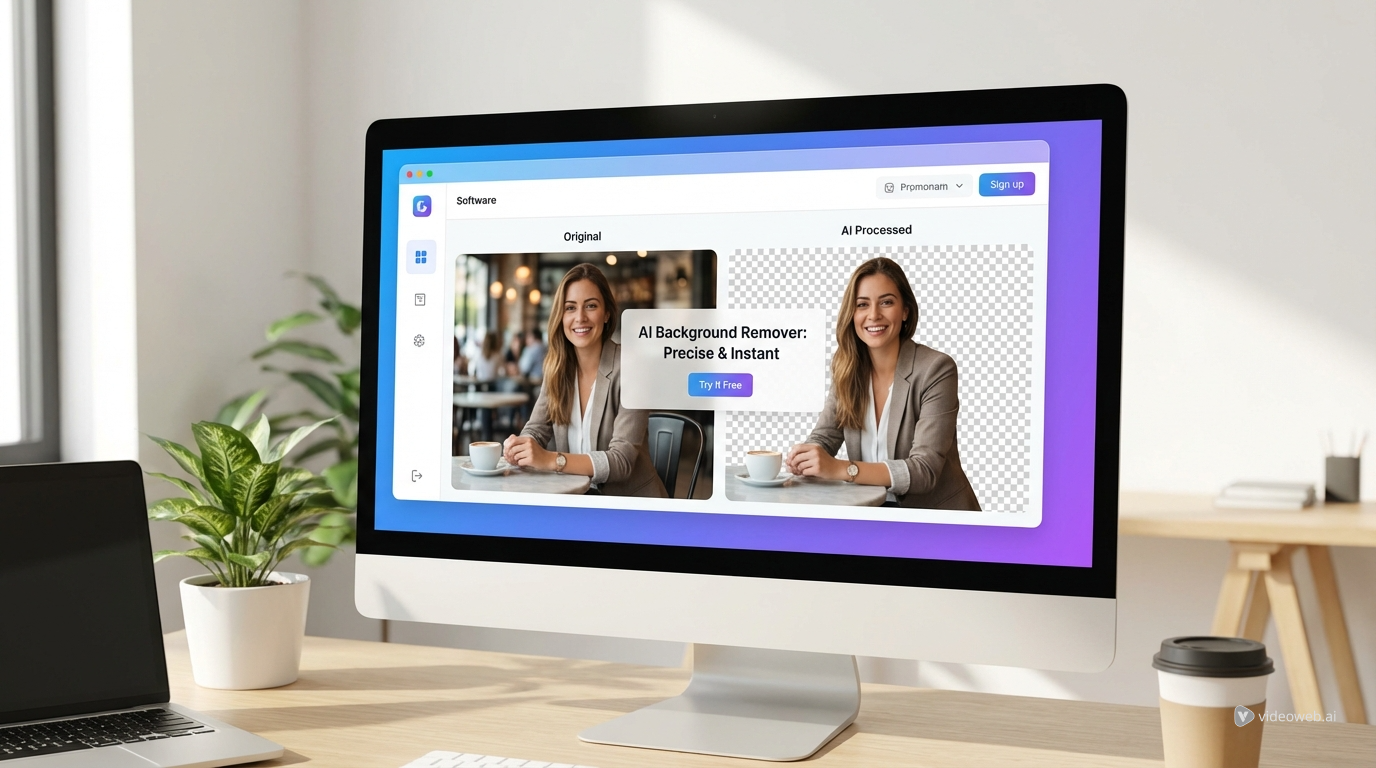
Rasakan Alat Kreasi AI Ajaib dengan AI Facefy yang Kuat
Ubah wajah dalam gambar dan video Anda secara instan menggunakan teknologi AI canggih kami, hasil berkualitas tinggi.
Video AI
Foto ke VideoGambar ke VideoTeks ke VideoVideo ke VideoGenerator Video Tarian AIGenerator Superman AITransformasi Hulk AIGenerator Video AI Veo 3.1Kontrol Gerak KlingGenerator Video Vidu Q1Generator Video AI LabubuPertumbuhan Rambut AIPertumbuhan Otot AIEfek AI SquishEfek AI VenomAnimasi Foto LamaVideo Jabat Tangan AIGenerator Video Terbang AIAI Balon Terbang
Gambar AI
Generator Gambar AIGPT Image 2.0Nano Banana 2 AINano Banana Pro AISeedream 4.5 AISeedream 5.0 AIGenerator Foto Headshot AIGenerator Potongan Rambut AIPemulih Foto LamaGenerator Mainan LabubuGenerator Hewan Peliharaan ke ManusiaGenerator Bayi AIGenerator Action Figure AIGenerator Seni GhibliGenerator AI HalloweenGambar GPT 1.5Nano Banana AISeedream 4.0 AI