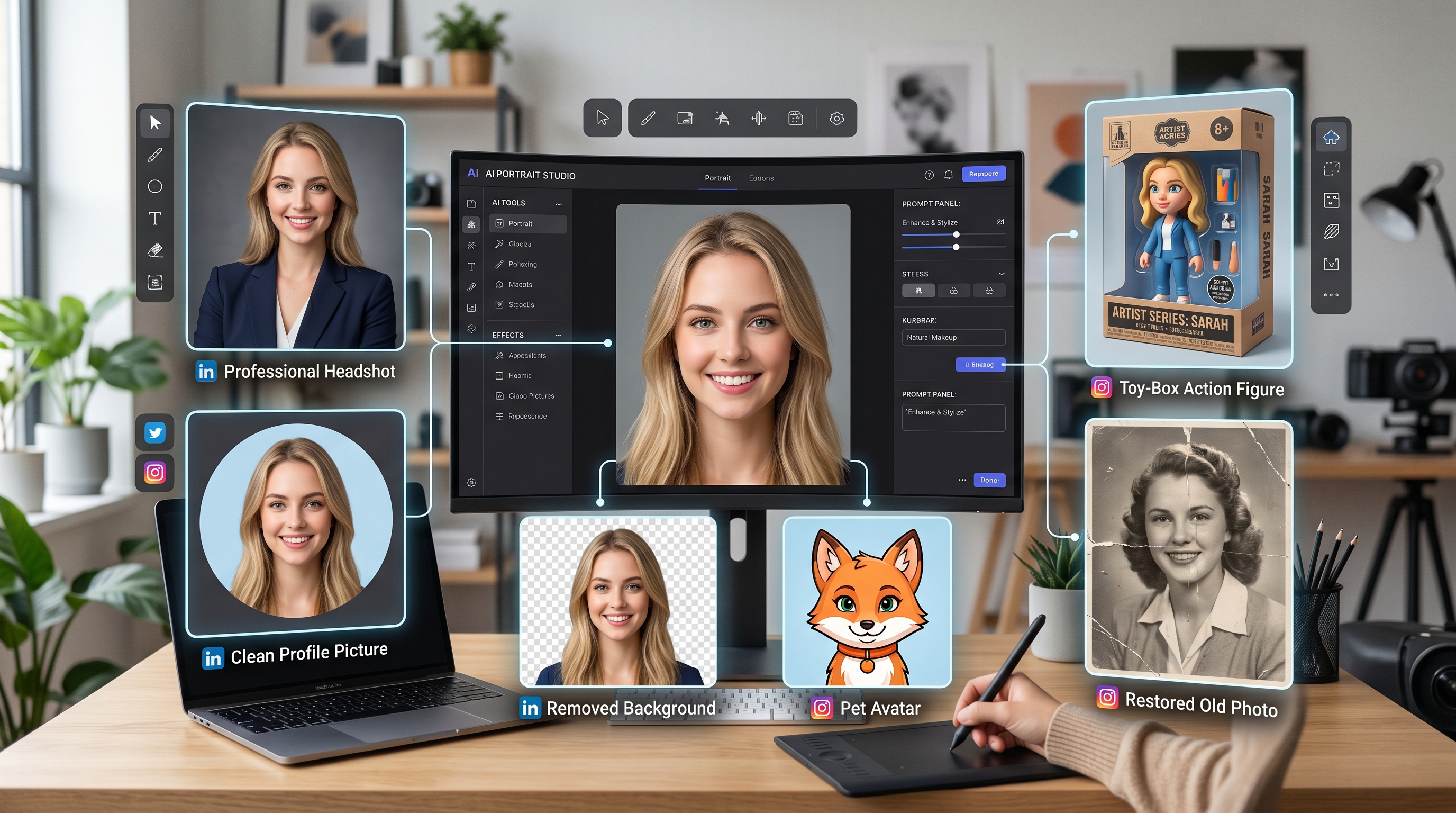
Erlebe magische KI-Kreationstools mit dem leistungsstarken AI Facefy
Verwandle Gesichter in deinen Bildern und Videos sofort mit unserer fortschrittlichen KI-Technologie und erziele Top-Ergebnisse.
Video-KI
Foto zu VideoBild zu VideoText zu VideoVideo-zu-VideoKI-TanzgeneratorKI-Superman-GeneratorKI-Hulk-TransformationVeo 3.1 KI-VideogeneratorKling BewegungssteuerungVidu Q1 VideogeneratorLabubu KI-VideogeneratorKI-HaarwachstumKI-MuskelwachstumKI-Quetsch-EffektKI-Venom-EffektAlte Foto-AnimationKI-Handschlag-VideoKI-Fliegender-Objekt-GeneratorKI-Ballonflug-Generator
Bild-KI
KI-BildgeneratorGPT Image 2.0Nano Banana 2 AINano Banana Pro KISeedream 4.5 KISeedream 5.0 AIKI-PorträtgeneratorKI-FrisurengeneratorAlte-Foto-RestaurierungLabubu-SpielzeuggeneratorHaustier-zu-Mensch-GeneratorKI-Baby-GeneratorKI-Actionfiguren-GeneratorGhibli-KunstgeneratorKI-Halloween-GeneratorGPT Bild 1.5Nano Banana KISeedream 4.0 KI