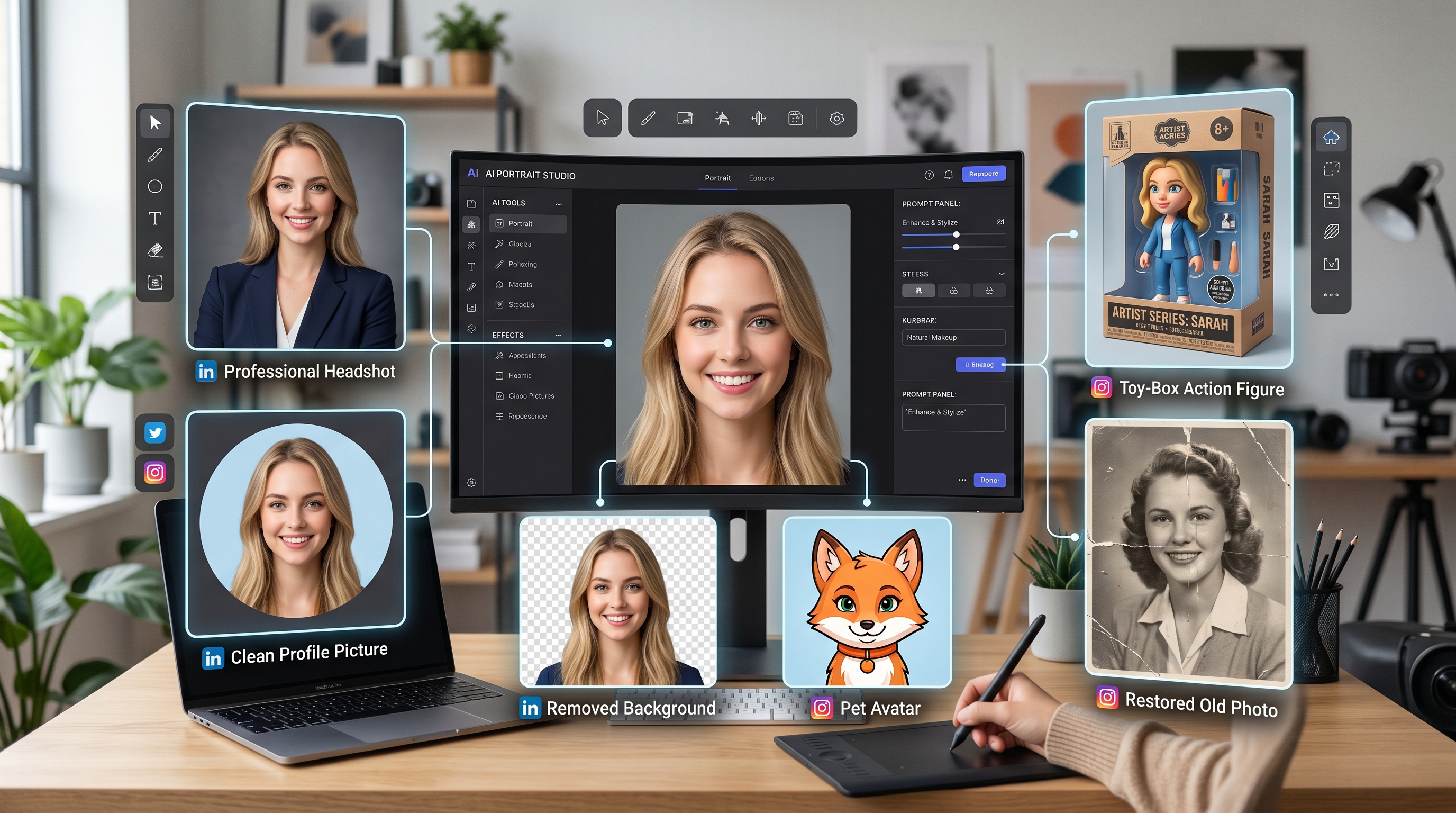
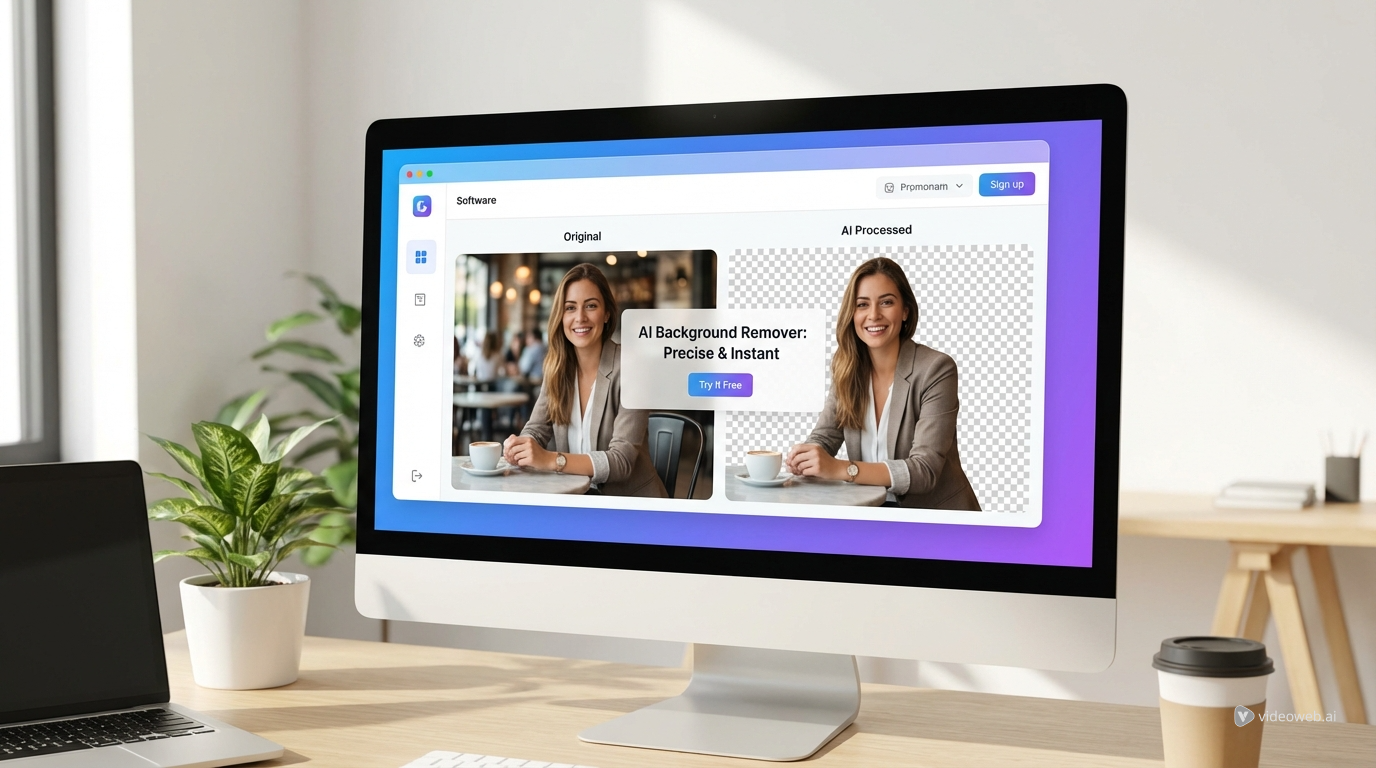
สัมผัสเครื่องมือสร้างสรรค์ AI สุดมหัศจรรย์กับ AI Facefy อันทรงพลัง
เปลี่ยนใบหน้าในภาพและวิดีโอของคุณได้ทันทีด้วยเทคโนโลยี AI อันทันสมัยของเรา พร้อมผลลัพธ์คุณภาพสูง
AI วิดีโอ
ภาพถ่ายเป็นวิดีโอรูปภาพเป็นวิดีโอข้อความเป็นวิดีโอแปลงวิดีโอเป็นวิดีโอเครื่องสร้างวิดีโอเต้นด้วย AIAI สร้างวิดีโอซูเปอร์แมนAI แปลงร่างเป็นฮัลค์Генератор видео с ИИ Veo 3.1Kling Motion ControlVidu Q1 Video Generatorสร้างวิดีโอตุ๊กตา Labubu ด้วย AIAI ผมยาวAI กล้ามเนื้อAI เอฟเฟกต์บีบAI เอฟเฟกต์ Venomแอนิเมชันภาพเก่าAI จับมือเครื่องสร้างวิดีโอบินด้วย AIAI บอลลูนลอย
AI รูปภาพ
เครื่องมือสร้างภาพด้วย AIGPT Image 2.0Nano Banana 2 AIนาโนบานาน่าโปร เอไอSeedream 4.5 AISeedream 5.0 AIสร้างภาพถ่ายหน้าด้วย AIสร้างทรงผมด้วย AIฟื้นฟูภาพถ่ายเก่าLabubu Toy GeneratorAI สัตว์เลี้ยงเป็นคนAI สร้างภาพเด็กAI สร้างฟิกเกอร์Ghibli Art Generatorเครื่องสร้างภาพฮาโลวีนด้วย AIGPT Image 1.5นาโน บานานา เอไอSeedream 4.0 AI