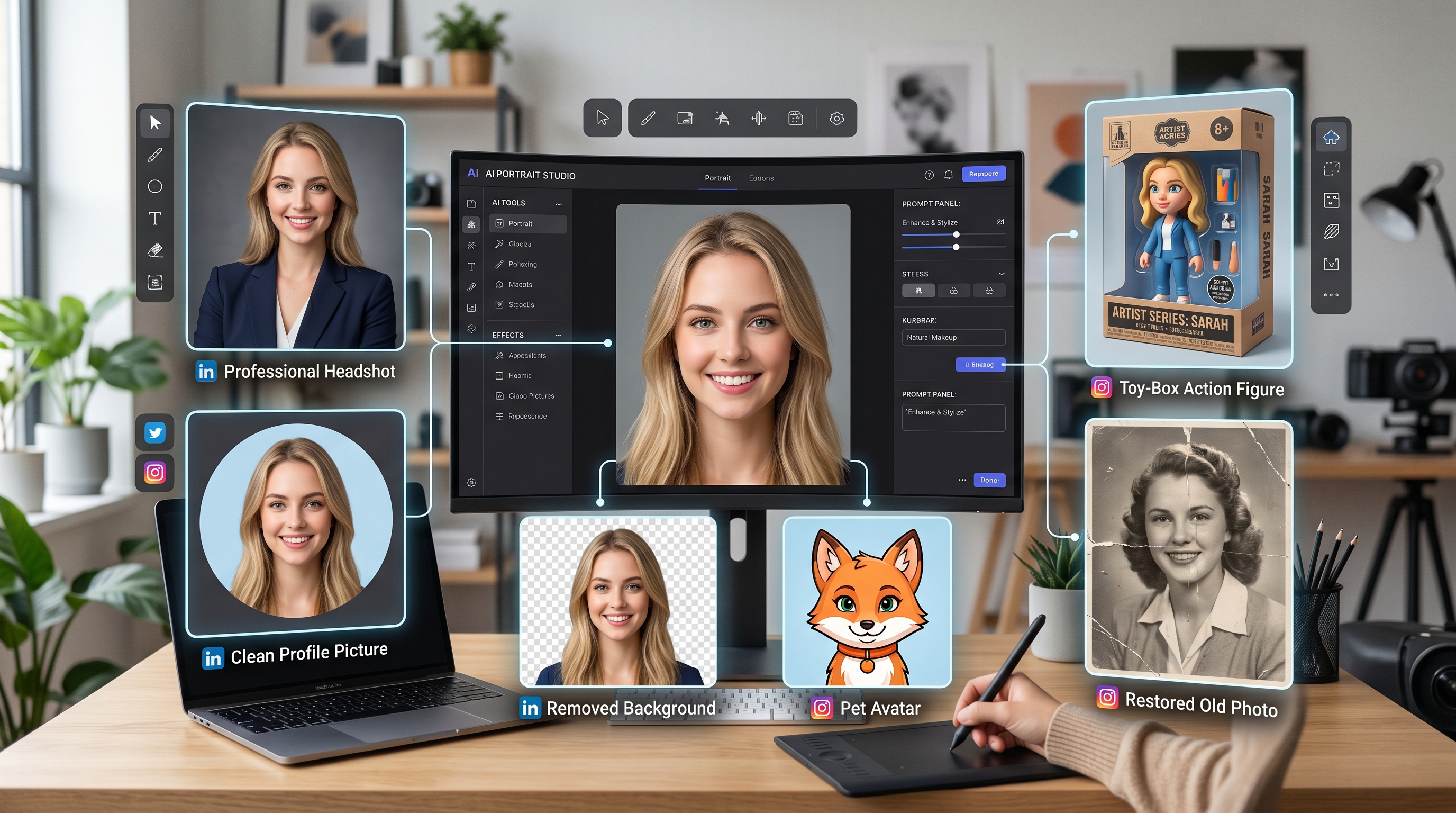
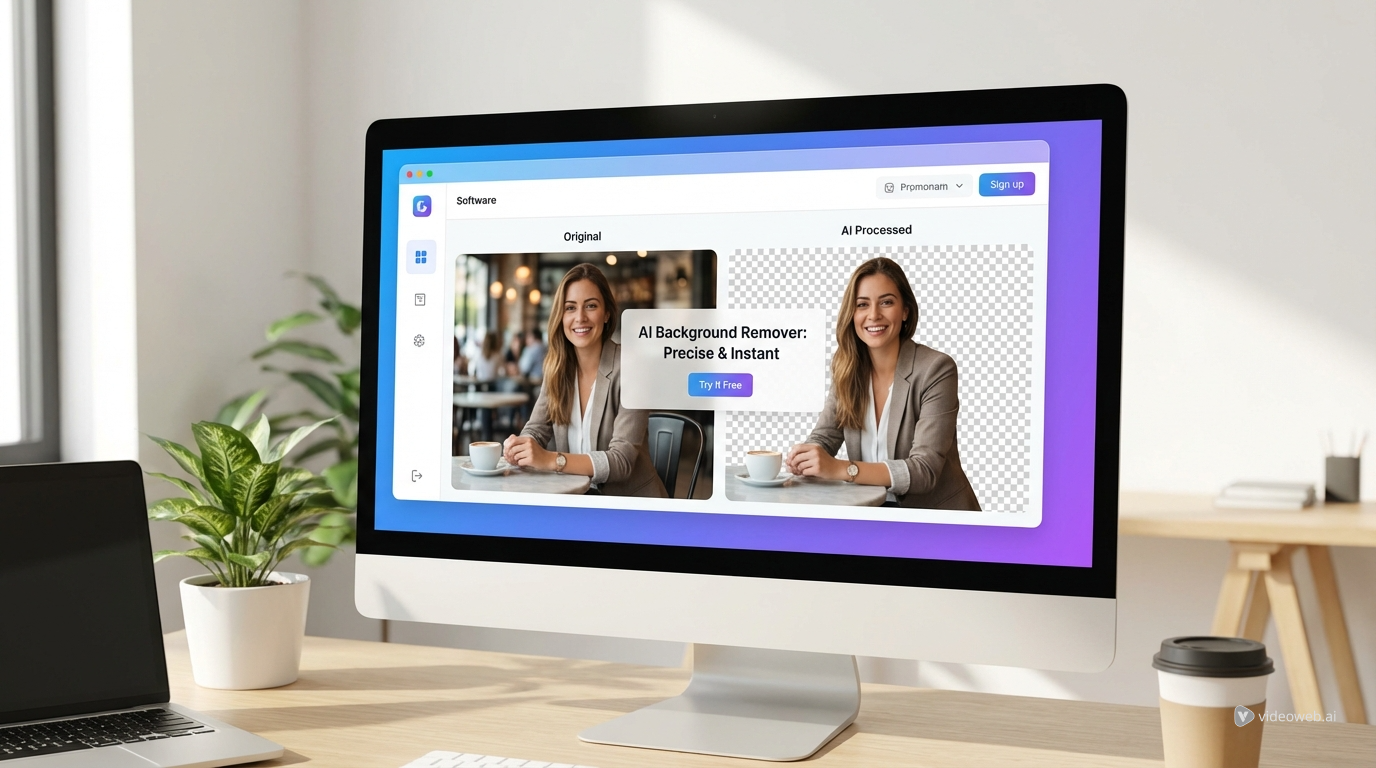
Experimenta Herramientas Mágicas de Creación IA con el potente AI Facefy
Transforma instantáneamente los rostros en tus imágenes y videos usando nuestra avanzada tecnología de IA, obteniendo resultados de la más alta calidad.
Video IA
Foto a videoImagen a videoTexto a videoVideo a VideoGenerador de Video de Baile IAGenerador de Superman IATransformación Hulk IAGenerador de Video IA Veo 3.1Control de Movimiento KlingGenerador de Video Vidu Q1Generador de videos Labubu con IACrecimiento de cabello IACrecimiento muscular IAEfecto Squish IAEfecto Venom IAAnimación de fotos antiguasVideo de apretón de manos IAGenerador de Video Volador IAGlobo Volador IA
Imagen IA
Generador de imágenes con IAGPT Image 2.0Nano Banana 2 AINano Banana Pro IASeedream 4.5 IASeedream 5.0 AIGenerador de Retratos IAGenerador de Cortes de Pelo IARestaurador de Fotos AntiguasGenerador de juguetes LabubuGenerador de mascota a humanoGenerador de bebés IAGenerador de figuras de acción IAGenerador de arte estilo GhibliGenerador de Halloween IAImagen GPT 1.5IA Nano BananaSeedream 4.0 IA