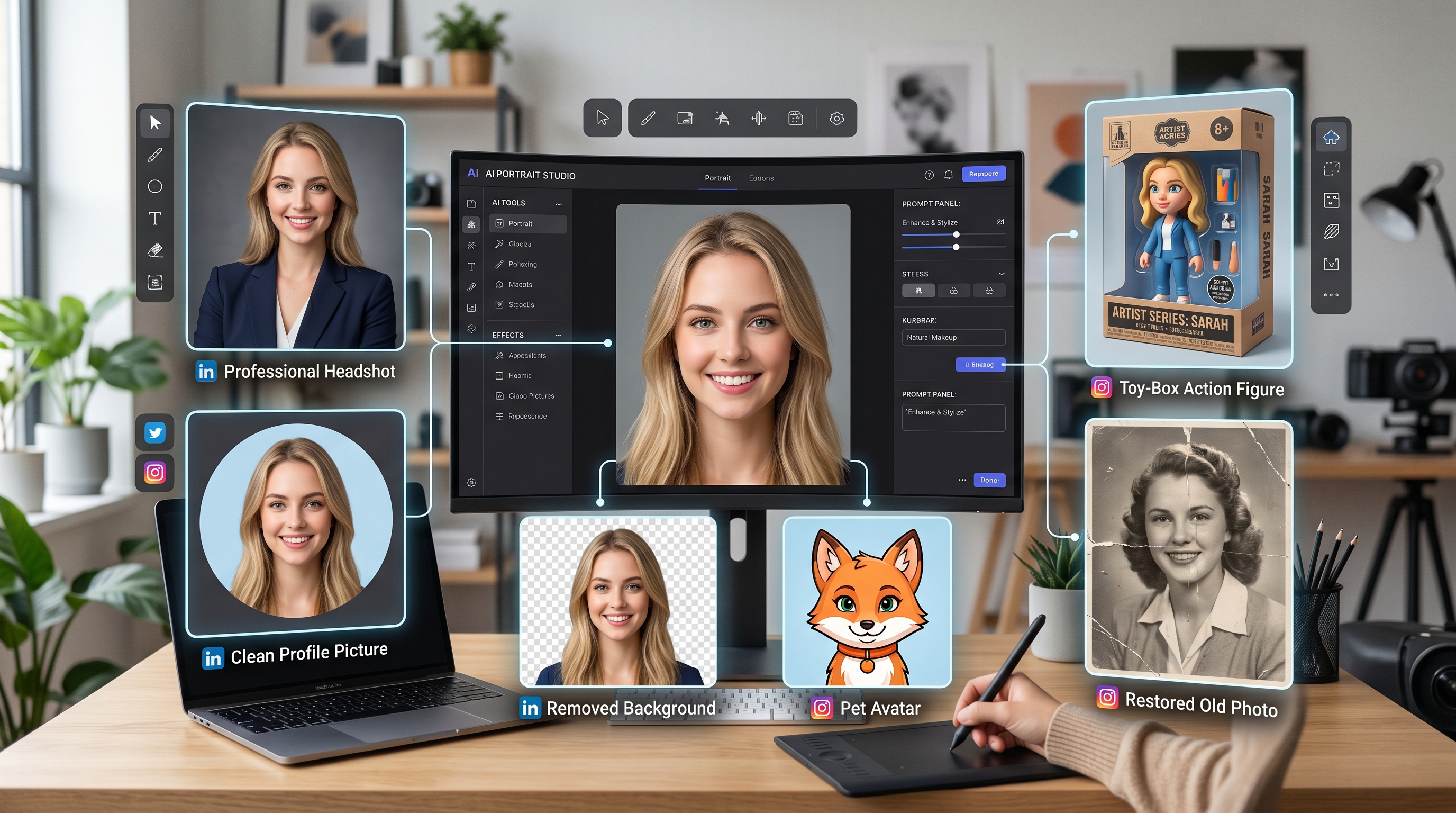
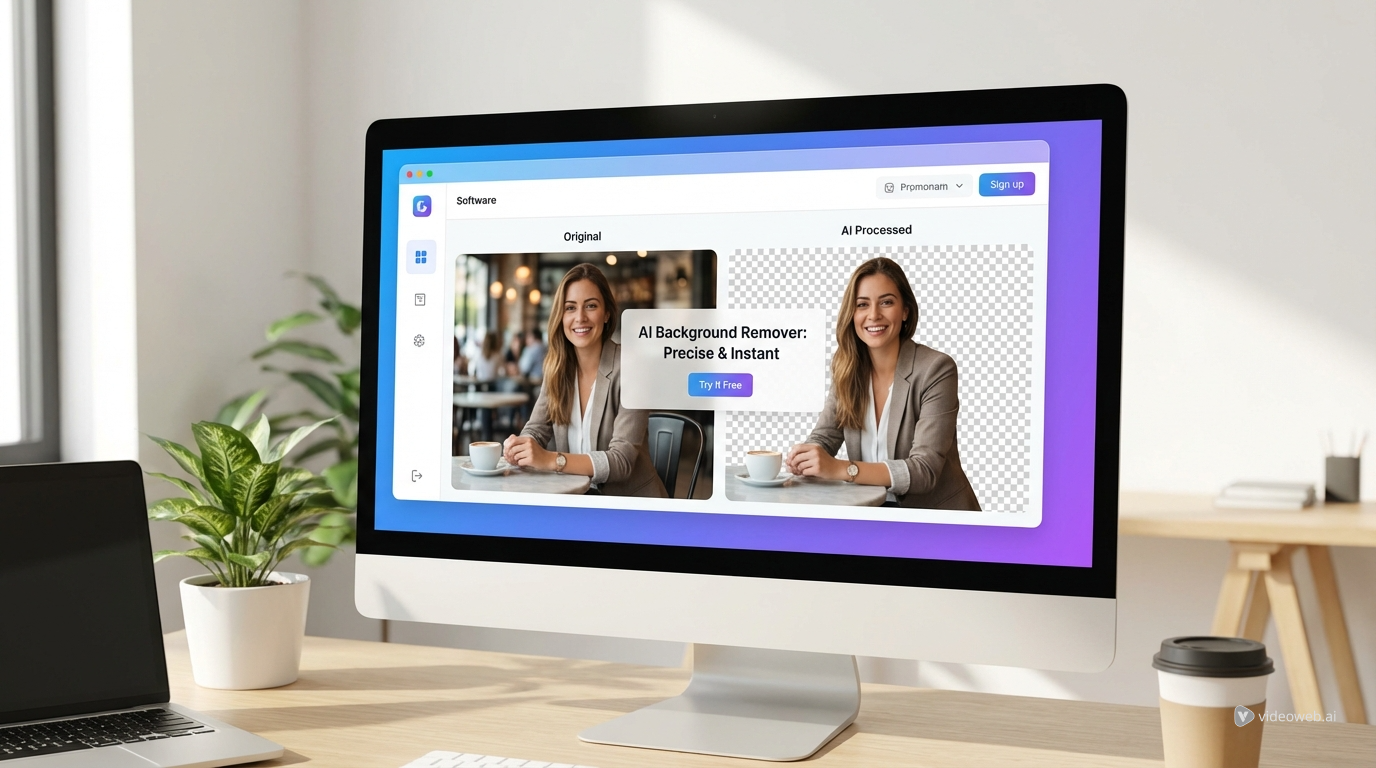
اختبر أدوات الإبداع السحرية بالذكاء الاصطناعي مع AI Facefy القوي
حوّل الوجوه في صورك وفيديوهاتك فورًا باستخدام تقنيات الذكاء الاصطناعي المتقدمة لدينا، لتحصل على أفضل النتائج.
ذكاء اصطناعي للفيديو
تحويل صورة إلى فيديوتحويل صورة إلى فيديوتحويل نص إلى فيديوتحويل الفيديو إلى فيديومولد فيديو الرقص بالذكاء الاصطناعيمولد سوبرمان بالذكاء الاصطناعيتحويل إلى هالك بالذكاء الاصطناعيمولد فيديو Veo 3.1 بالذكاء الاصطناعيالتحكم في حركة الفيديو بواسطة كليـنغمولد فيديو Vidu Q1مولد فيديو لابوبو بالذكاء الاصطناعينمو الشعر بالذكاء الاصطناعينمو العضلات بالذكاء الاصطناعيتأثير الضغط بالذكاء الاصطناعيتأثير السم بالذكاء الاصطناعيتحريك الصور القديمةفيديو المصافحة بالذكاء الاصطناعيمولد فيديو الطيران بالذكاء الاصطناعيبالون يطير بالذكاء الاصطناعي
ذكاء اصطناعي للصور
مولد الصور بالذكاء الاصطناعيGPT Image 2.0Nano Banana 2 AIنانو بنانا برو للذكاء الاصطناعيسيدريم 4.5 للذكاء الاصطناعيSeedream 5.0 AIمولد صور البورتريه بالذكاء الاصطناعيمولد قصات الشعر بالذكاء الاصطناعيترميم الصور القديمةمولد دمية Labubuتحويل صورة الحيوان إلى إنسانمولد صور الأطفال بالذكاء الاصطناعيمولد شخصيات الأكشن بالذكاء الاصطناعيمولد فن جيبليمولد الهالوين بالذكاء الاصطناعيصورة GPT 1.5الذكاء الاصطناعي نانو بناناسيدريم 4.0 للذكاء الاصطناعي