深入了解 AI Facefy 的最新文章、新聞和更新。獲取專家見解、教學,並隨時了解我們突破性的人工智慧技術和平台發展。
在 AIFacefy 上使用 Happy Horse 1.0,將一張圖片轉換成帶有動態、音訊和實用提示的短篇 AI 影片。
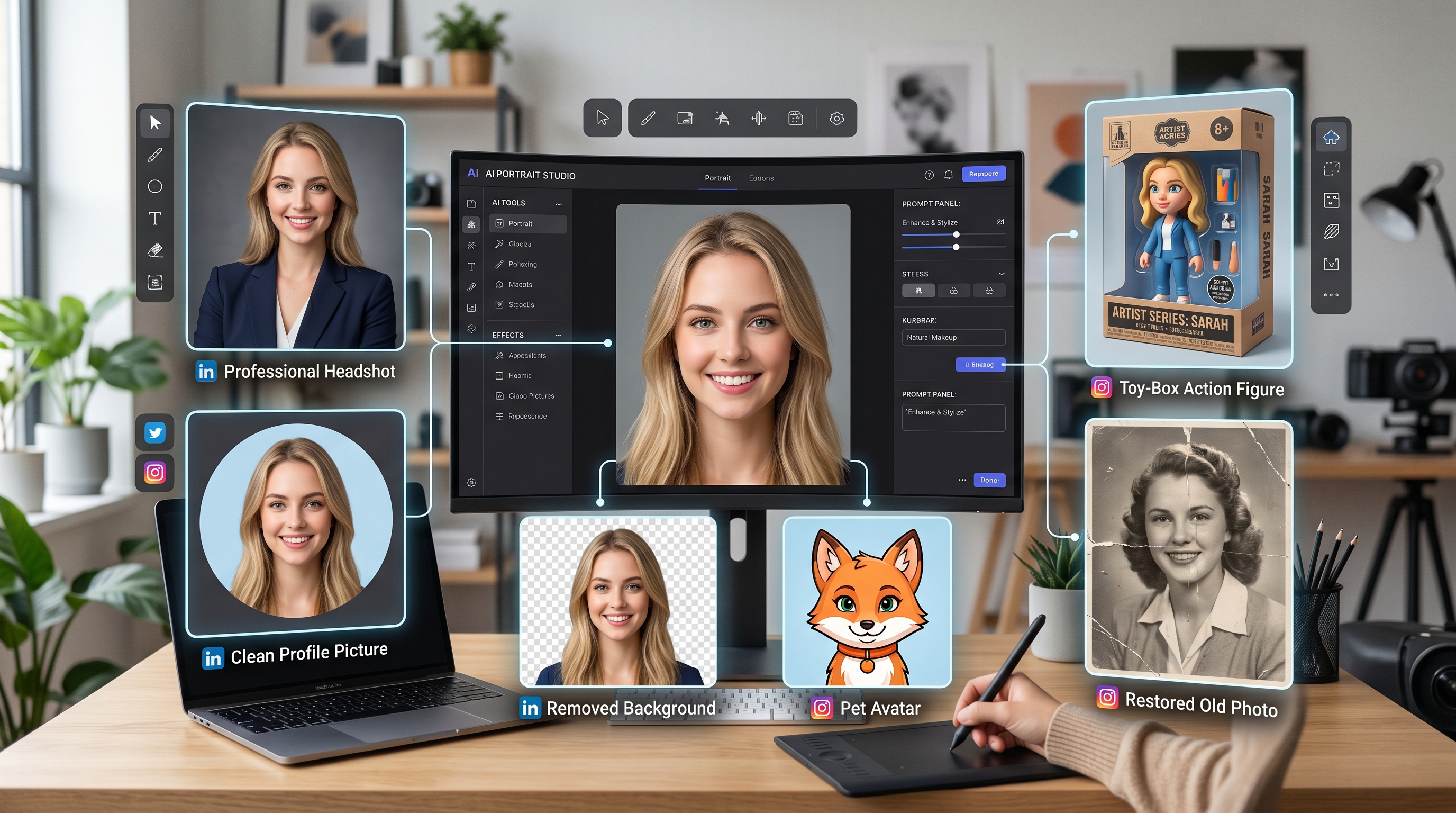
使用 GPT Image 2 和 AIFacefy 工具編輯頭像、背景、虛擬人物、公仔以及個人檔案照片。
探索 GPT Image 2:有哪些新功能、在哪裡可以使用,以及它為何在寫實人像生成方面表現出色。
Sora 2 即將關閉。請比較 Veo 3.1、Seedance 2、Grok Imagine 和 Kling 3.0,然後為創作者找出最佳替代方案。
使用 AI 臉部合成和嬰兒生成器建立數位家庭相簿。使用 AIFacefy,您可以輕鬆且逼真地想像角色或未來的孩子。
使用 AIFacefy,透過適合嬰兒、寵物及迷因的「以圖生舞」工作流程,創作爆紅的 TikTok 舞蹈短片。
試用 AI 臉部評分工具比較人像照片,然後使用 Nano Banana 2 編輯並優化表現最好的那張照片。
了解如何存取 Seedance 2.0、其 API 狀態代表什麼意義,以及為何它正成為最值得關注、最令人興奮的 AI 影片工具之一。
了解 Higgsfield 動態控制如何透過簡單的工作流程技巧、提示語建議,以及實用的 AIFacefy 工具,提升 AI 影片的一致性。
Seedance 2.0 實測評測:實際優勢、限制與 20 分鐘測試方案——外加在 AIFacefy 上快速試用類似工作流程的方法。
Unbiased Mind Video AI 評測:功能介紹、品質測試、價格建議,以及在需要可控且可重複結果時,何時 AIFacefy 工具是更佳替代方案。
Kling 3.0 即將推出——以下是你可以期待的更新內容、它與 Kling 2.6 的差異,以及為什麼 AIFacefy 是你現在開始使用的最佳選擇。
在 AIFacefy 上使用 Kling Motion Control 製作 AI 舞蹈影片——運用動作參考、可直接複製的提示詞,並掌握導出到 TikTok、Reels 和 YouTube Shorts 的技巧。
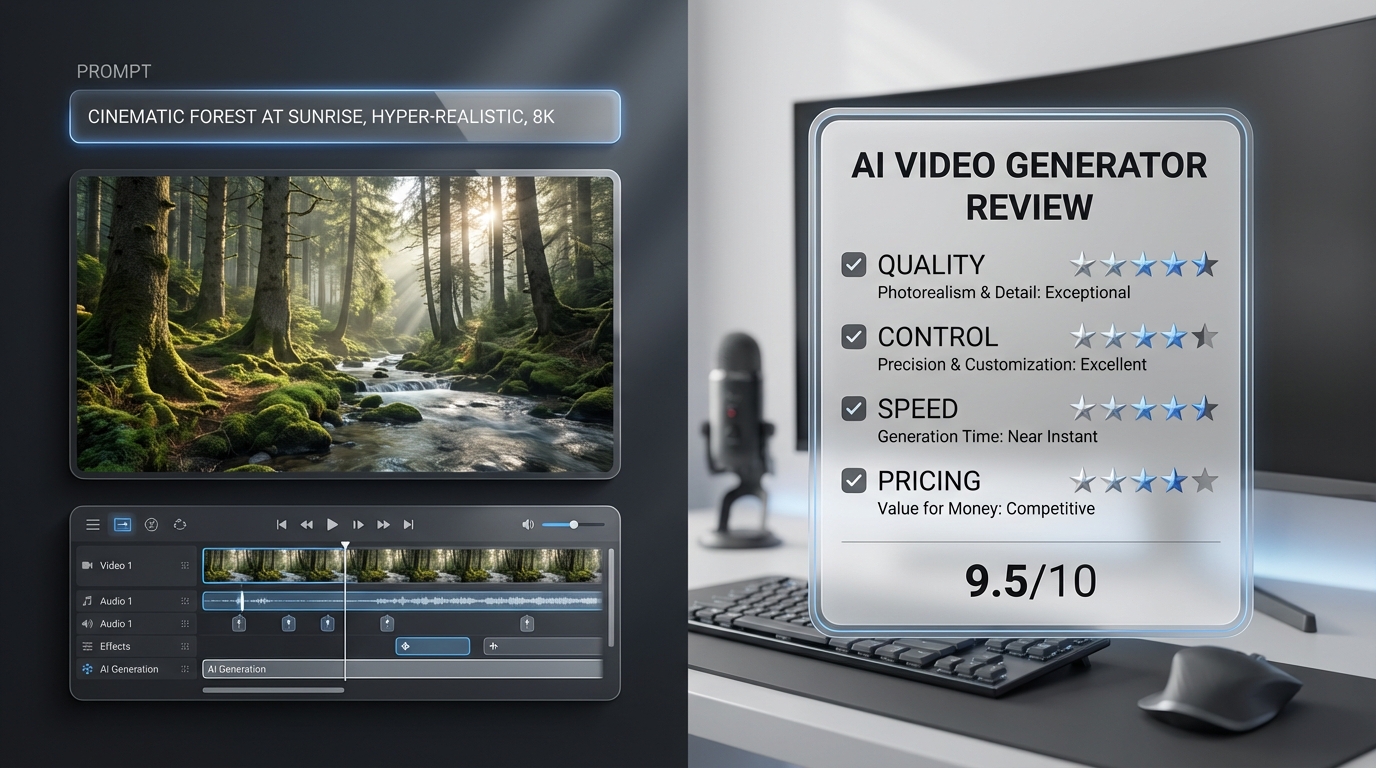
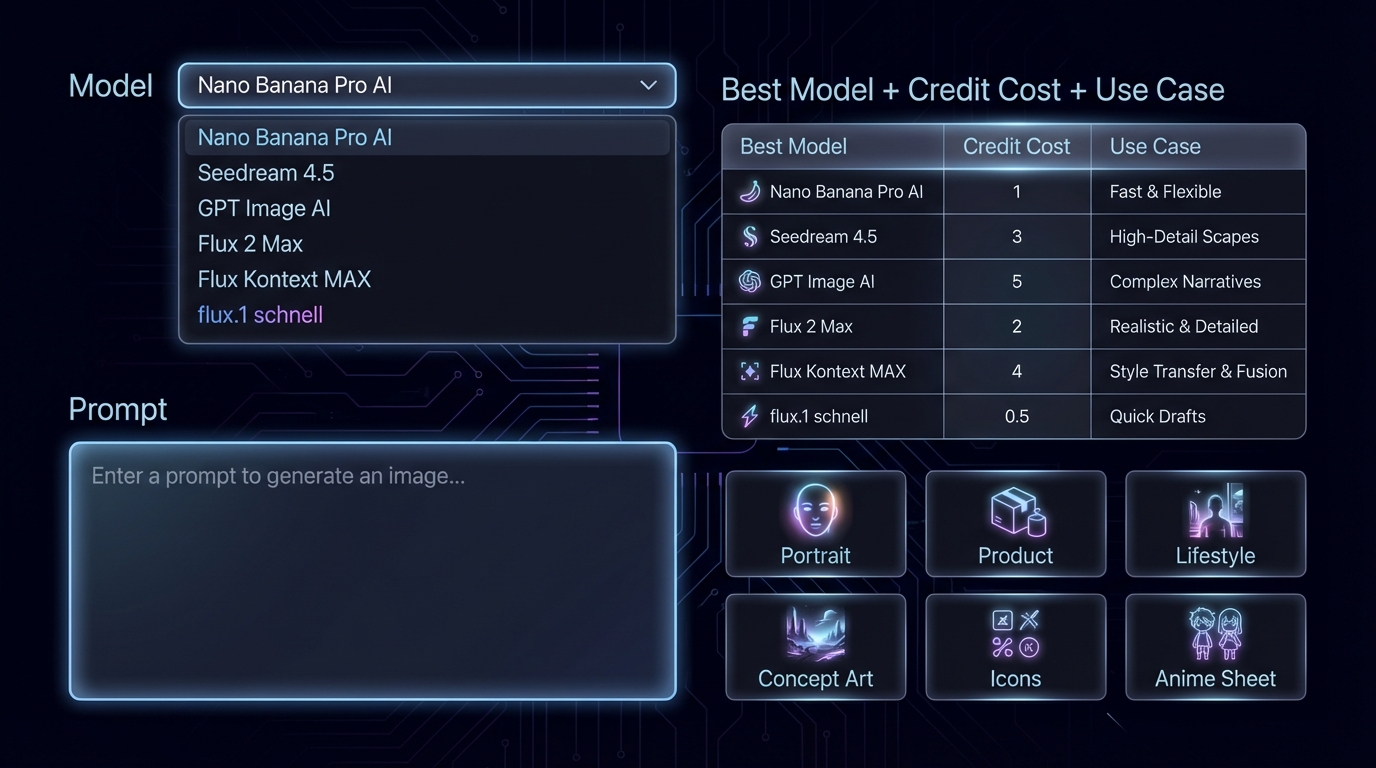
AIFacefy 的 AI 影像生成器透過快速圖表與提示範例比較頂尖模型,使您能快速選擇合適引擎並節省點數。
學習如何使用Nano Banana、Google Gemini 2.5 Flash Image AI生成一致的角色,適用於故事敘述、品牌塑造和設計專案。